
KoreanFoodie's Study
딥러닝 튜토리얼 3강 1부, 신경망과 활성화 함수 - 밑바닥부터 시작하는 딥러닝 본문
딥러닝 튜토리얼 3강 1부, 신경망과 활성화 함수 - 밑바닥부터 시작하는 딥러닝
GoldGiver 2019. 11. 4. 16:34
해당 포스팅은 한빛 미디어에서 출판한 '밑바닥부터 시작하는 딥러닝'이라는 교재의 내용을 따라가며 딥러닝 튜토리얼을 진행하고 있습니다. 관련 자료는 여기에서 찾거나 다운로드 받으실 수 있습니다.
퍼셉트론에서 신경망으로
- 신경망의 예
신경망을 그림으로 나타낸 예시를 보자.

Input이라고 표시된 것은 입력층, 맨 오른쪽 줄(Output)을 출력층, 중간 층(Hidden)을 은닉층이라고 한다. 은닉층의 뉴런은 사람 눈에는 보이지 않는다. 0층의 입력층, 1층이 은닉층, 2층이 출력층이 된다.
- 퍼셉트론 복습
기존 퍼셉트론은 이런 구조를 하고 있다.

# 식 :
y = 0 (b + w1x1 + w2x2 <= 0)
또는
y = 1 (b + w1x1 + w2x2 > 0)여기서 b는 편향을 나타내는 매개변수로, 뉴런이 얼마나 쉽게 활성화되느냐를 제어한다. 한편, w1과 w2는 각 신호의 가중치를 나타내는 매개변수로, 각 신호의 영향력을 제어한다.
이때, 편향값 b를 반영한 퍼셉트론을 그리면 다음과 같은 형태가 된다.

위의 식을 다시 간단화 시키면, 다음과 같이 표현할 수 있다.
# 식 :
y = h(b + w1x1 + w2x2)
h(x) = 0 (x <= 0)
또는
h(x) = 1 (x > 0)입력 신호의 총합이 h(x)라는 함수를 거쳐 변환되어, 변환된 값이 y의 출력이 됨을 보여준다. 결과적으로 각 식이 하는 일은 같다.
- 활성화 함수의 등장
위의 h(x)처럼, 입력 신호의 총합을 출력 신호로 변환하는 함수를 일반적으로 활성화 함수(activation function)이라고 한다. '활성화'라는 이름이 말해주듯 활성화 함수는 입력 신호의 총합이 활성화를 일으키는지를 정하는 역할을 한다.
이제, 위의 식을 조금 변형해보자.
# 식 :
a = b + w1x1 + w2x2
y = h(a)위의 식을 반영한 퍼셉트론을 그려보면 다음과 같다.

즉, 가중치 신호를 조합한 결과가 a라는 노드(=뉴런)가 되고, 활성화 함수 h()를 통과하여 y라는 노드로 변환되는 과정을 잘 살펴볼 수 있다.
활성화 함수
위의 식과 같은 활성화 함수는 입계값을 경계로 출력이 바뀌는데, 이런 함수를 계단 함수(step function)이라고 한다. 그리서 "퍼셉트론에서는 활성화 함수로 계단 함수를 이용한다"라 할 수 있다. 그리고, 활성화 함수를 계단 함수에서 다른 함수로 변경하는 것이 신경망의 세계로 나아가는 열쇠이다!
- 시그모이드 함수
다음은 신경망에서 자주 이용하는 활성화 함수인 시그모이드 함수(sigmoid function)을 나타낸 식이다.
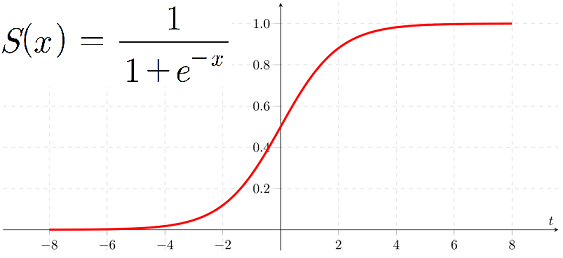
시그모이드 함수에 1.0과 2.0을 입력하면 h(1.0) = 0.731..., h(2.0) = 0.880...과 같은 특정 값을 출력한다.
신경망에서는 활성화 함수로 시그모이드 함수를 이용하여 신호를 변환하고, 그 변환된 신호를 다음 뉴런에 전달한다. 사실 이전 포스트에서 본 퍼셉트론과 앞으로 볼 신경망의 주된 차이는 이 활성화 함수뿐이다. 그러면 활성화 함수로 이용되는 시그모이드 함수를 계단 함수와 비교하면서 자세히 살펴보자.
- 계단 함수 구현하기
파이썬으로 계단 함수를 작성해 보자.
def step_function(x):
if x > 0:
return 1
else:
return 0이 구현은 단순하지만, 인자 x가 넘파이 배열을 인수로 받을 수 없다. 조금 수정해 보자.
import numpy as np
def step_function(x):
y = x > 0
return y.astype(np.int)
x = np.array([-1., 1., 2.])
step_function(x) # result : array([0, 1, 1])넘파이 배열에 부등호 연산을 수행하면 배열의 원소 각각에 부등호 연산을 수행한 bool 배열이 생성된다. (0보다 크면 True, 0보다 작거나 같으면 False)
위의 함수에서 y는 bool type 배열이다. 그런데 우리가 원하는 계단 함수는 0이나 1의 'int형'을 출력하는 함수이다. 그래서 배열 y의 원소를 bool에서 int형으로 바꿔준다.
- 계단 함수의 그래프
이제 앞서 정의한 계단 함수를 그래프로 그려보자!
import numpy as np
import matplotlib.pyplot as plt
def step_function(x):
return np.array(x > 0, dtype=np.int)
x = np.arange(-5.0, 5.0, 0.1)
y = step_function(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()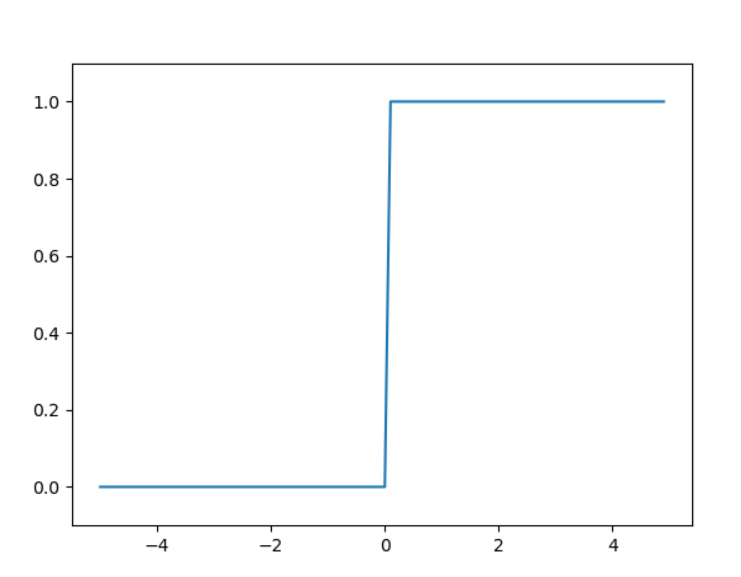
계단함수는 0 값을 경계로 계단처럼 값이 바뀌게 됨을 확인할 수 있다!
- 시그모이드 함수 구현하기
이제 시그모이드 함수를 구현해 보자.
def sigmoid(x):
return 1 / (1 + np.exp(-x))이것을 적용하려면, y = step_function(x)부분을 y = sigmoid(x)로 바꾸어 주기만 하면 된다.
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()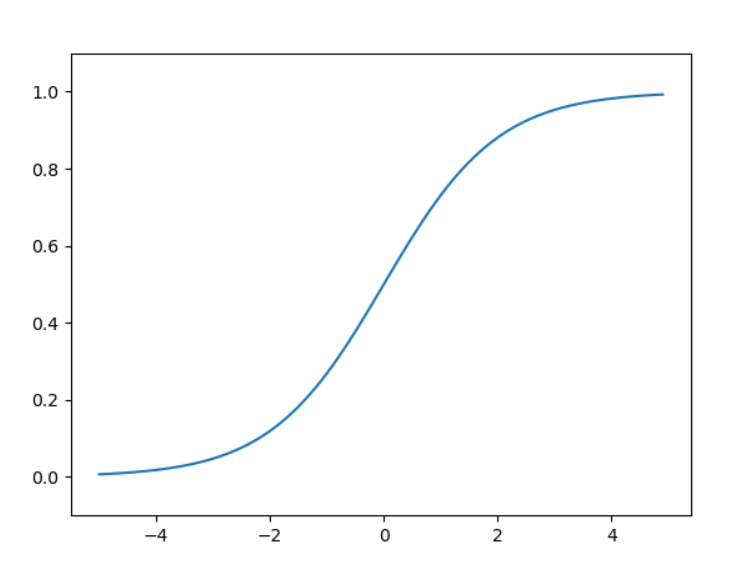
- 시그모이드 함수와 계단 함수 비교
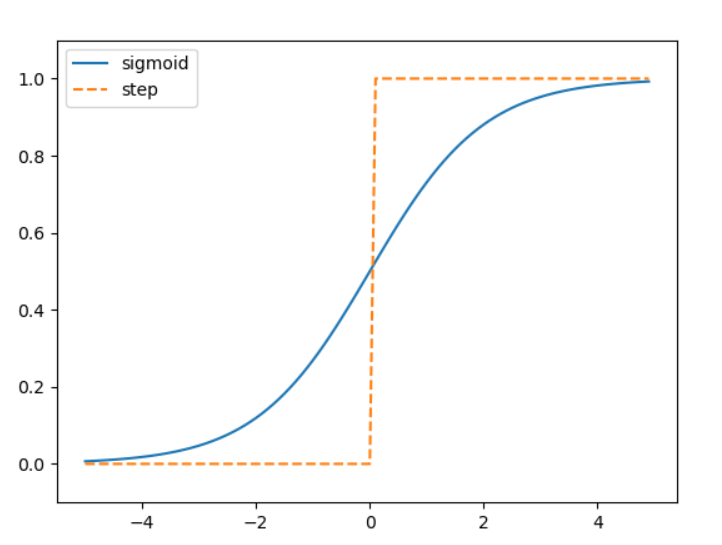
시그모이드 함수는 부드러운 곡선이며 입력에 따라 출력이 연속적으로 변화한다.
한편, 계단 함수는 0을 경계로 출력이 갑자기 바뀌어 버린다. 시그모이드 함수의 이 매끈함이 신경망 학습에서 아주 중요한 역할을 하게 된다.
- 비선형 함수
계단 함수와 시그모이드 함수는 둘 다 비선형 함수라는 공통점이 있다.
무언가 입력했을 때 출력이 입력의 상수배만큼 변하는 함수를 선형 함수라고 하고, 직선 1개로는 그릴 수 없는 함수를 비선형 함수라고 한다.
신경망에서는 활성화 함수로 비선형 함수를 사용해야 한다. 달리 말하면 선형 함수를 사용해서는 안 된다.
왜 선형 함수는 안되는 걸까? 그 이유는 바로 선형 함수를 이용하면 신경망의 층을 깊게 하는 의미가 없기 때문이다!
선형 함수의 문제는 층을 아무리 깊게 해도 '은닉층이 없는 네트워크'로도 똑같은 기능을 할 수 있다는 데 있다.
예를 들어 h(x) = cx라는 활성화 함수가 있다고 해 보자. 은닉층이 3층이라면,
y = h(h(h(x))) = c * c * c * x가 된다. 즉, y = c * c * c * x처럼, 실은 하나의 식으로 축소시킬 수 있다!
이는, 은닉층이 없는 네트워크로 표현할 수 있다는 뜻이다.
위의 예처럼, 선형 함수를 이용해서는 여러 층으로 구성하는 이점을 살릴 수 있으며, 층을 쌓는 혜택을 얻고 싶다면 활성화 함수로는 반드시 비선형 함수를 사용해야 한다.
- ReLU 함수
시그모이드 함수는 신경망 분야에서 오래전부터 이용해왔으나, 최근에는 ReLU(Rectified Linear Unit, 렐루)함수를 주로 이용한다.
ReLU는 입력이 0을 넘으면 그 입력을 그대로 출력하고, 0 이하이면 0을 출력하는 함수이다. 구현은 매우 간단하다.
def relu(x):
return np.maximum(0, x) # return the larger one
다차원 배열의 계산
다차원 배열의 계산은, 그냥 행렬 계산을 의미한다. 예시를 통해 계산이 어떻게 이루어지는지 보자.
import numpy as numpy
A = np.array([1, 2, 3, 4])
np.ndim(A) # 배열의 차원 수 확인, 1차원!
A.shape # (4, )
A.shape[0] # 4다른 예시도 한 번 보자.
import numpy as numpy
B = np.array([1, 2], [3, 4], [5, 6]])
np.ndim(B) # 2 -> 2차원이다!
B.shape # (3, 2)위처럼, 2차원 배열은 특히 행렬(matrix)라고 부르고, 배열의 가로 방향을 행(row), 세로 방향을 열(column)이라고 한다.
- 행렬의 곱

행렬의 곱은 위처럼 왼쪽 행렬의 행(가로)과 오른쪽 행렬의 열(세로)을 원소별로 곱하고 그 값들을 더해서 계산한다.
이 계산을 파이썬으로 확인해 보자.
import numpy as np
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
print(np.dot(A,B)) # [[19 22]
# [43 50]]np.dot()를 활용하면, 두 행렬의 곱을 간단히 구할 수 있다!
다만, 주의할 점이 2가지가 있다.
-
np.dot(A, B)와 np.dot(B, A)는 다른 결과값을 산출한다
-
행렬의 곱에서는 대응하는 차원의 원소 수를 일치시켜야 한다
예를 들어, 행렬 A가 3 X 2이고, B가 2 X 4이면, A의 열(2)와 B의 행(2)가 일치하므로, np.dot(A, B)는 3 X 4 짜리의 행렬을 결과값으로 내보낸다. A 행렬과 B 행렬의 곱셈에서, 앞 행렬의 열과 뒤 행렬의 행의 크기가 일치해야 한다!
- 신경망에서의 행렬 곱
넘파이 행렬을 써서 신경망을 구현해 보자.

이 구현에서, X, W, Y의 형상을 주의해서 보자. 특히, X와 W의 대응하는 차원의 원소 수가 같아야 한다.
import numpy as np
X = np.array([1, 2])
W = np.array([[1, 3, 5], [2, 4, 6]])
Y = np.dot(X, W)
print(Y) # [ 5 11 17]이번에는 신경망과 활성화 함수들에 대해 알아보았다. 신경망 구현 및 MNIST 실습 등은 다음 포스트에서 다뤄보도록 하겠다.
'Deep Learning > 밑바닥부터 시작하는 딥러닝 1' 카테고리의 다른 글
| 딥러닝 튜토리얼 4강 2부, 수치 미분과 학습 알고리즘 - 밑바닥부터 시작하는 딥러닝 (0) | 2019.11.07 |
|---|---|
| 딥러닝 튜토리얼 4강 1부, 신경망 학습 - 밑바닥부터 시작하는 딥러닝 (7) | 2019.11.07 |
| 딥러닝 튜토리얼 3강 2부, 신경망 설계, 소프트 맥스 - 밑바닥부터 시작하는 딥러닝 (0) | 2019.11.05 |
| 딥러닝 튜토리얼 2강, 퍼셉트론(Perceptron) 개념 익히기 - 밑바닥부터 시작하는 딥러닝 (0) | 2019.11.04 |
| 딥러닝 튜토리얼 1강, 넘파이(Numpy) 다루기 - 밑바닥부터 시작하는 딥러닝 (0) | 2019.11.03 |



